[译] Spark高效范围连接 (Spark Efficient Range-Joins)
如果你有用Spark进行过时间序列分析,你可能会碰到这种情况:根据时间戳范围进行JOIN。
本文我们假设有两个DataFrame,
events,带有时间戳字段eventTimemeasurements,带有时间戳字段measurementTime
我们想要把每个事件和一小时内的测量值合并。
一种显而易见的方法是使用范围条件查询,形如measurementTime BETWEEN eventTime - n AND eventTime
,这将导致JOIN操作进行一次完整的笛卡尔乘积然后执行过滤。
这种做法的效率很低,尤其是当数据量达到数十万的情况下。
尽管Spark社区正在研究(译注:已经merge)通用方案(Github Issue), 但仍然存在一些情况,我们可以提升其性能。本文将介绍我的实现方式, 如果你的场景不同,可能需要些许转作以解决你的问题。
数据
为了简单起见,下文将使用以下两个DataFrame。
你也可以使用自己的类,只要他们含有时间戳或者数字类型字段。
本文使用时间戳为例。
Events
root
|-- eid: long (nullable = false)
|-- eventTime: timestamp (nullable = true)
|-- eventType: string (nullable = true)可以使用一下代码生成随机数据
case class Event(eid:Long, eventTime:java.sql.Timestamp, eventType:String)
val randomEventTypeUDF = udf(() => List("LoginEvent", "PurchaseEvent", "DetailsUpdateEvent")(Random.nextInt(3)))
def generateEvents(n:Long):Dataset[Event] = {
val events = sqlContext.range(0,n).select(
col("id").as("eid"),
// eventTime is just being set to an event every 10 seconds.
(unix_timestamp(current_timestamp()) - lit(10)*col("id")).cast(TimestampType).as("eventTime"),
randomEventTypeUDF().as("eventType")
).as[Event]
events
}
generateEvents(5).toDF.show
// +---+--------------------+------------------+
// |eid| eventTime| eventType|
// +---+--------------------+------------------+
// | 0|2016-09-12 15:46:...| PurchaseEvent|
// | 1|2016-09-12 15:46:...|DetailsUpdateEvent|
// | 2|2016-09-12 15:46:...|DetailsUpdateEvent|
// | 3|2016-09-12 15:45:...|DetailsUpdateEvent|
// | 4|2016-09-12 15:45:...| LoginEvent|
// +---+--------------------+------------------+
Measurements
root
|-- mid: long (nullable = false)
|-- measurementTime: timestamp (nullable = true)
|- value: double (nullable = false)同样,可以使用以下代码生成随机的Measurements:
case class Measurement(mid:Long, measurementTime:java.sql.Timestamp, value:Double)
def generateMeasurements(n:Long):Dataset[Measurement] = {
val measurements = sqlContext.range(0,n).select(
col("id").as("mid"),
// measurementTime is more random, but generally every 10 seconds
(unix_timestamp(current_timestamp()) - lit(10)*col("id") + lit(5)*rand()).cast(TimestampType).as("measurementTime"),
rand(10).as("value")
).as[Measurement]
measurements
}
generateMeasurements(5).toDF.show
// +---+--------------------+-------------------+
// |mid| measurementTime| value|
// +---+--------------------+-------------------+
// | 0|2016-09-12 15:46:..|0.41371264720975787|
// | 1|2016-09-12 15:46:...| 0.1982919638208397|
// | 2|2016-09-12 15:46:..|0.12030715258495939|
// | 3|2016-09-12 15:46:..|0.44292918521277047|
// | 4|2016-09-12 15:45:...| 0.8898784253886249|
// +---+--------------------+-------------------+
The Naive Approach 不加思考的方法
最显而易见的方法是直接JOIN两个DadaFrame并指定范围条件,代码如下:
import org.apache.spark.unsafe.types.CalendarInterval
var events = generateEvents(1000000)
var measurements = generateMeasurements(1000000)
// An example with a timestamp field would look like this:
val res = events.join(measurements,
(measurements("measurementTime") > events("eventTime") - CalendarInterval.fromString("interval 30 seconds") ) &&
(measurements("measurementTime") <= events("eventTime"))
)
// With a numeric field (took the id as an example, this is obviously useless):
val res = events.join(measurements,
(measurements("mid") > events("eid") - lit(2)) &&
(measurements("mid") <= events("eid"))
)
res.explain
// run something like `res.count` to make Spark actually perform the join.
我们通过explain命令来查看Spark将如何执行我们的JOIN操作。
== Physical Plan ==
CartesianProduct ((measurementTime#178 > eventTime#162 - interval 30 seconds) && (measurementTime#178 <= eventTime#162))
:- *Project [id#156L AS eid#161L, cast((1474876784 - (10 * id#156L)) as timestamp) AS eventTime#162, UDF() AS eventType#163]
: +- *Range (0, 1000000, splits=4)
+- *Filter isnotnull(measurementTime#178)
+- *Project [id#172L AS mid#177L, cast((cast((1474876784 - (10 * id#172L)) as double) + (5.0 * rand(6122355864398157384))) as timestamp) AS measurementTime#178, rand(10) AS value#179]
+- *Range (0, 1000000, splits=4)通过第一行,我们可以知道Spark将会进行一次笛卡尔乘积以完成JOIN操作。
另外,如果JOIN的一方足够小的话,Spark会广播小表到所有的机器以执行BroadcastNestedLoopJoin和BroadcastExchange。
译注:显然,这种方法是O(n^2)的,而且会造成大量的shuffle
The Bucketing, Double-Joining and Filtering Approach 分桶合并过滤法
在上面的方法中,我们明知道我们只对一小时内的测量值感兴趣,却进行了完整的笛卡尔乘积,这毫无疑问是对算力的浪费。 所以解决问题的关键是让每个事件只和时间接近的记录匹配。
所以我们可以把记录分成若干个桶,每个桶是一个小时:
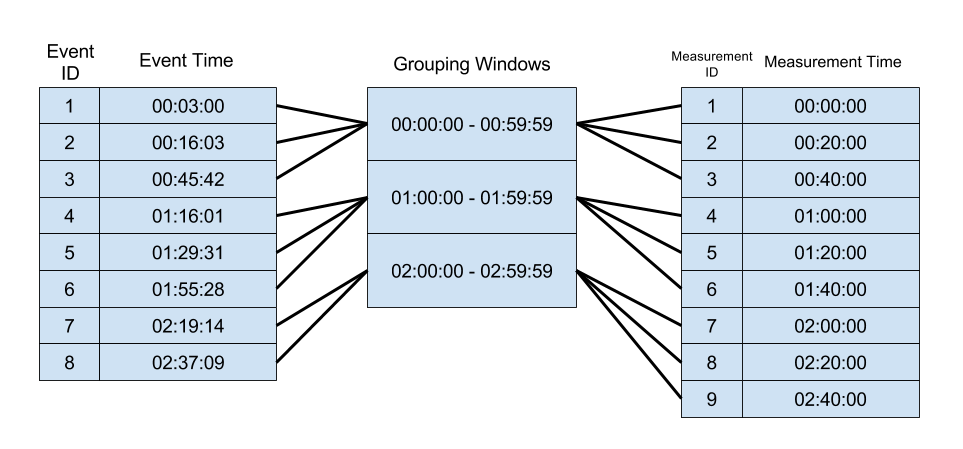
对于一条给定的event,无论他在窗口的那个位置(60分钟的第一分钟或是最后一分钟), 我们都可以断定和他匹配的所有的measurement都在同一个桶或者前一个桶里
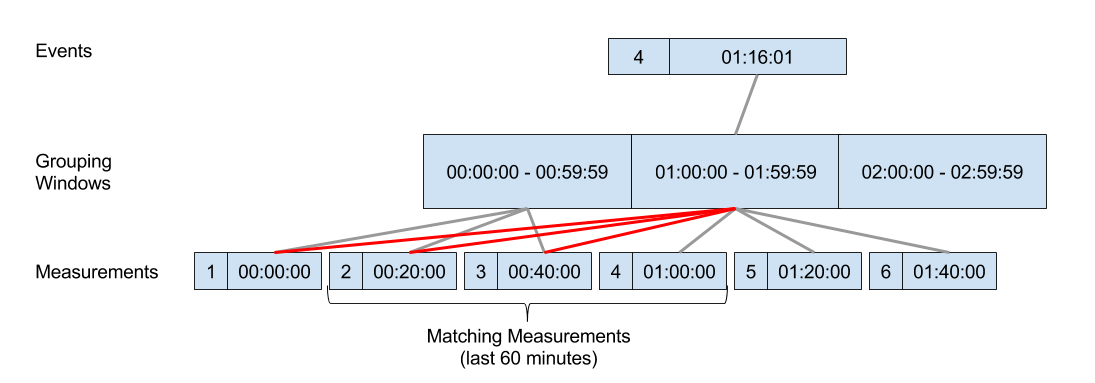
所以我们要做的事情就是
- 把所有events分到匹配的桶里
- 把所有measurements连接到匹配的桶以及前一个桶里
- 现在我们可以通过桶的id进行连接,并过滤60分钟内的测量值
代码如下
import scala.util.{ Try, Success, Failure }
def range_join_dfs[U,V](df1:DataFrame, rangeField1:Column, df2:DataFrame, rangeField2:Column, rangeBack:Any):Try[DataFrame] = {
// check that both fields are from the same (and the correct) type
(df1.schema(rangeField1.toString).dataType, df2.schema(rangeField2.toString).dataType, rangeBack) match {
case (x1: TimestampType, x2: TimestampType, rb:String) => true
case (x1: NumericType, x2: NumericType, rb:Number) => true
case _ => return Failure(new IllegalArgumentException("rangeField1 and rangeField2 must both be either numeric or timestamps. If they are timestamps, rangeBack must be a string, if numerics, rangeBack must be numeric"))
}
// returns the "window grouping" function for timestamp/numeric.
// Timestamps will return the start of the grouping window
// Numeric will do integers division
def getWindowStartFunction(df:DataFrame, field:Column) = {
df.schema(field.toString).dataType match {
case d: TimestampType => window(field, rangeBack.asInstanceOf[String])("start")
case d: NumericType => floor(field / lit(rangeBack))
case _ => throw new IllegalArgumentException("field must be either of NumericType or TimestampType")
}
}
// returns the difference between windows and a numeric representation of "rangeBack"
// if rangeBack is numeric - the window diff is 1 and the numeric representation is rangeBack itself
// if it's timestamp - the CalendarInterval can be used for both jumping between windows and filtering at the end
def getPrevWindowDiffAndRangeBackNumeric(rangeBack:Any) = rangeBack match {
case rb:Number => (1, rangeBack)
case rb:String => {
val interval = rb match {
case rb if rb.startsWith("interval") => org.apache.spark.unsafe.types.CalendarInterval.fromString(rb)
case _ => org.apache.spark.unsafe.types.CalendarInterval.fromString("interval " + rb)
}
//( interval.months * (60*60*24*31) ) + ( interval.microseconds / 1000000 )
(interval, interval)
}
case _ => throw new IllegalArgumentException("rangeBack must be either of NumericType or TimestampType")
}
// get windowstart functions for rangeField1 and rangeField2
val rf1WindowStart = getWindowStartFunction(df1, rangeField1)
val rf2WindowStart = getWindowStartFunction(df2, rangeField2)
val (prevWindowDiff, rangeBackNumeric) = getPrevWindowDiffAndRangeBackNumeric(rangeBack)
// actual joining logic starts here
val windowedDf1 = df1.withColumn("windowStart", rf1WindowStart)
val windowedDf2 = df2.withColumn("windowStart", rf2WindowStart)
.union( df2.withColumn("windowStart", rf2WindowStart + lit(prevWindowDiff)) )
val res = windowedDf1.join(windowedDf2, "windowStart")
.filter( (rangeField2 > rangeField1-lit(rangeBackNumeric)) && (rangeField2 <= rangeField1) )
.drop(windowedDf1("windowStart"))
.drop(windowedDf2("windowStart"))
Success(res)
}
代码其实并不复杂,大多是对时间戳和数字的处理。现在再让我们来看看Spark的执行计划。
var events = generateEvents(10000000).toDF
var measurements = generateMeasurements(10000000).toDF
// you can either join by timestamp fields
var res = range_join_dfs(events, events("eventTime"), measurements, measurements("measurementTime"), "60 minutes")
// or by numeric fields (again, id was taken here just for the purpose of the example)
var res = range_join_dfs(events, events("eid"), measurements, measurements("mid"), 2)
res match {
case Failure(ex) => print(ex)
case Success(df) => df.explain
}
// and run something like `res.count` to actually perform anything.
运行代码(注意使用较大的DataFrame,否则Spark可能会进行广播优化),将得到如下的执行计划
== Physical Plan ==
*Project [eid#1449L, eventTime#1450, eventType#1451, mid#1469L, measurementTime#1470, value#1471]
+- *SortMergeJoin [windowStart#1486], [windowStart#1494], Inner, ((measurementTime#1470 > eventTime#1450 - interval 30 seconds) && (measurementTime#1470 <= eventTime#1450))
:- *Sort [windowStart#1486 ASC], false, 0
: +- Exchange hashpartitioning(windowStart#1486, 200)
: +- *Project [eid#1449L, eventTime#1450, eventType#1451, window#1492.start AS windowStart#1486]
: +- *Filter ((isnotnull(eventTime#1450) && (eventTime#1450 >= window#1492.start)) && (eventTime#1450 < window#1492.end))
: +- *Expand (...)
: +- *Project (...)
: +- *Range (0, 10000000, splits=4)
+- *Sort [windowStart#1494 ASC], false, 0
+- Exchange hashpartitioning(windowStart#1494, 200)
+- Union
:- *Project [mid#1469L, measurementTime#1470, value#1471, window#1500.start AS windowStart#1494]
: +- *Filter (((isnotnull(measurementTime#1470) && (measurementTime#1470 >= window#1500.start)) && (measurementTime#1470 < window#1500.end)) && isnotnull(window#1500.start))
: +- *Expand (...)
: +- *Filter isnotnull(measurementTime#1470)
: +- *Project (...)
: +- *Range (0, 10000000, splits=4)
+- *Project (...)
+- *Expand (...)
+- *Filter isnotnull(measurementTime#1470)
+- *Project (...)
+- *Range (0, 10000000, splits=4)注意到这里使用了SortMergeJoin而不是CatesianProduct
Benchmarking 基准测试
为了评估性能提升,我使用了一个由4台常规机器和1个master组成的集群来测试不同尺寸的数据。 结果如下
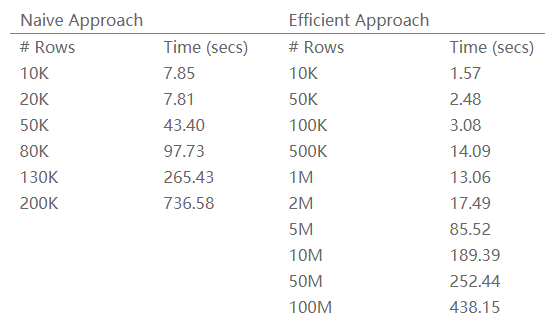
性能提升非常明显,优化前处理130K数据的时间,在优化后可以处理50M数据。 可以看到表中左侧数据较少,是因为处理更大的数据可能要花几个小时,所以我放弃了...
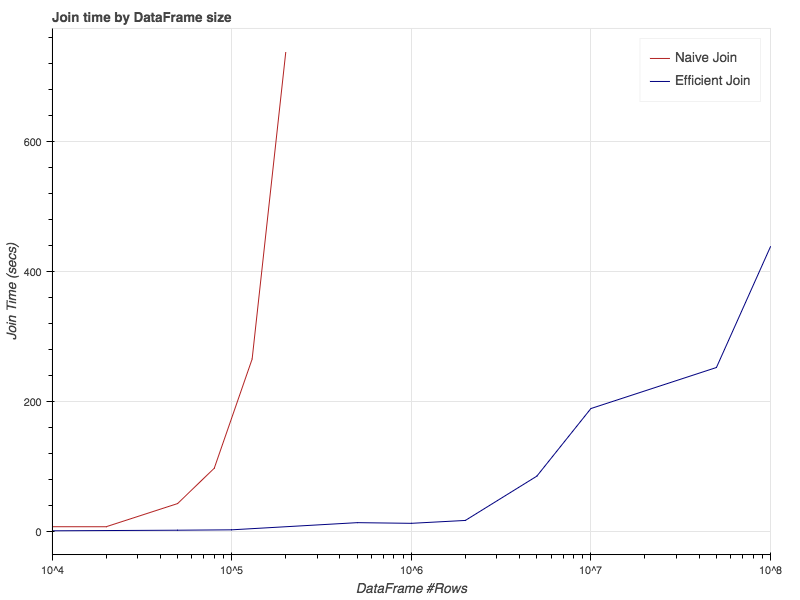
请注意,图中的x轴是对数轴,实际的性能提升约为3个数量级。
译注
文中的代码虽然全面但是略显繁琐,简化后可以写作以下代码
val eventBucket = events.withColumn("bucket", floor($"value" / 10))
val measurementBucket = measurements.withColumn("bucket", floor($"value" / 10))
val result = eventBucket.join(measurementBucket.union(measurementBucket.withColumn("bucket", $"bucket" + 1)), "bucket")
.filter(measurementBucket("value").between(eventBucket("value") - 10, eventBucket("value")))