大数据和分布式计算发展简史

在当今这个时代,大数据已经不是什么新鲜的名词了。 但凡是小有规模的公司,都配备了专门的数据部门。 而且这里的公司可不只是互联网公司,而是涵盖了能源,医疗,通信,零售,娱乐等等。 以至于数据本身成为了一种宝贵的资产,谁拥有了数据就拥有了未来。
但是,光有数据还不够,数据本身不会说话。我们需要对数据进行处理和挖掘。 这中间就需要用到我们的主角——分布式计算。
如果你是软件相关从业人员并且关心行业新闻,一定对Hadoop,Hive,Yarn,Spark这些技术如雷贯耳。 任何技术都不是一蹴而就的,它们的诞生是随着历史的演进,偶然亦或必然地被选择。
注:分布式计算和大数据并非同义词,本文仅讨论重合部分的一个分支
前Hadoop时代
在Hadoop出现之前,虽然不乏有MPI之类分布式计算方案,但是解决大型计算主要靠的还是单机。(当然,还要感谢伟大的数据库技术) 比如IBM的大型机不仅卖的贵,而且卖得好。

但是这么贵的机器不是每个公司都能用得起的,IBM的客户主要是政府、银行、保险和大型制造企业。
时间来到2004年,彼时Google刚刚上市,估值230亿。 Google做搜索引擎起家,天生就有大量数据。 面对日益膨胀的数据,初出茅庐的小G同学就在想, 强大的单机那么贵,我能不能多用一点便宜的机器也把事情给办了呢? 这个想法被Google写进了三篇论文当中,而这也让未来十年的霸主Hadoop呼之欲出。
Hadoop时代
在大数据近20年的发展里,Hadoop无疑是最为浓墨重彩的一笔。 这一切都开始于Google的三篇论文:
- 2003年,GFS: The Google File System
- 2004年,MapReduce: Simplified Data Processing on Large Clusters
- 2006年,Bigtable: A Distributed Storage System for Structured Data
这三篇论文以及对应的技术后来被誉为Google大数据的三驾马车。 他们分别解决了大数据的三个问题:分布式文件系统,分布式计算,分布式数据库。
但是,可惜的是,Google只发表了论文,而没有提供实现。 虽然Google声称这些技术已经在内部广泛使用,但是整个社区却未能受益。
而正是在这个空档期,天才程序员Doug Cutting在拜读了Google的大作之后,决定自己造轮子。 Doug Cutting同时还是最流行的开源搜索引擎Lucence/Nutch的作者,彼时正好在构建Nutch的分布式版本。 于是他“伙同” Mike Cafarella写下了GFS的一个实现,NDFS,亦即后来的HDFS。 第二年(2005),他又基于Google的第二篇论文实现了MapReduce。 次年(2006),Doug加入了Google的竞争对手Yahoo,并重新命名这一套系统为Hadoop。 至此,Hadoop正式登上历史舞台。 接下来的数年,各种分布式软件井喷式出现,不断壮大Hadoop生态。
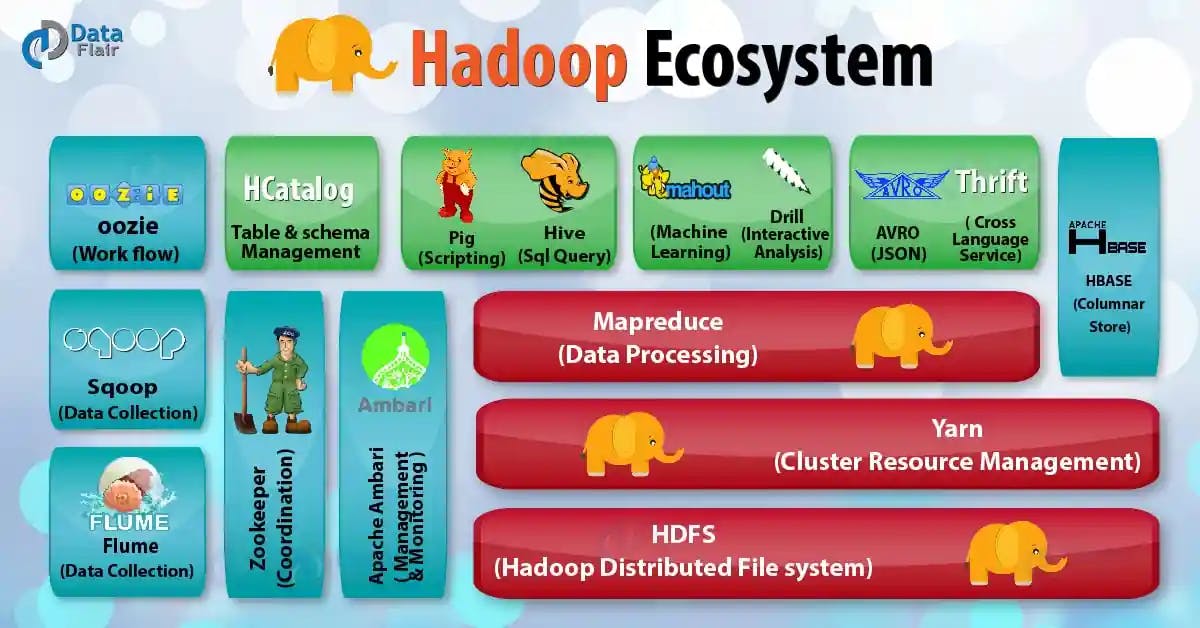
- HBase(2008),分布式非关系数据库,Google Big Table的实现
- Pig(2008),可编译成MapReduce程序的脚本语言
- Zookeeper(2008),分布式协调系统
- Mahout(2009),分布式机器学习库
- Hive(2010),SQL语法执行MapReduce大数据计算
- Yarn(2012),分布式资源调度系统
Hadoop本身较Google的论文来说并没有很大的创新,但是他的出现顺应了历史潮流。 21世纪初正是互联网快速发展的年代,大量公司对数据处理有需求。 Hadoop不仅开源免费,而且只需要廉价的机器就可以完成大规模运算,迅速就占领了市场。
不知道多年以后Google回首往事是否会后悔,原本可能只是想秀一秀技术,却激起千层浪。 而他自己却做了打工仔,没有在浪潮之中占到什么便宜。 也可能正是经此一役让Google明白了开源的重要性,在未来的Tensorflow,K8S,AlphaGo中果断开源。
另一方面,Hadoop在商业上也取得了成功
早年开源软件皆靠诸位开源运动人士在业界做社区用户推广,这波人本身毫无金钱汇报全靠一腔精神热血。 但本质上来说,人类以及人类社会都是趋利性的,没有利益驱动的市场行为终究无法持续。 因此,早期没有找到合适盈利模式的开源软件一直发展缓慢,靠类似 Richard Stallman 类似开源黑客斗士去做市场推广,市场效率之低下。 后期,在 Linux 商业公司红帽逐步摸索出开源软件变现模式后,其他开源软件也纷纷仿效。 Hadoop 一时间背后迅速成立三家公司,包括 Cloudera、HotonWorks、MapR,这些公司盈利潜力完全都依赖于 Hadoop 开源生态的规模, 因此,三家公司都会尽不遗余力地推进 Hadoop 生态发展,反过来促进了 Hadoop 整个生态用户的部署采用率。到大数据市场更后期的时代,其商业竞争更趋激烈。 以 Kafka、Spark、Flink 等开源大数据软件为例,在各自软件提交到 Apache 基金会之时创始人立刻创办商业公司,依靠商业推进开源生态建设, 同时通过收割生态最终反哺商业营收。
Google的论文打开了大数据时代的大门,Hadoop的巨大成功又打响了大数据时代的第一枪。大数据技术的发展还在继续,
后Hadoop时代
虽然标题叫做“后Hadoop”时代,但是这并不意味着Hadoop已经落幕。 后起之秀们更多的是在专攻一点,逐步蚕食Hadoop的领域。
Hadoop的痛点之一就是MapReduce过于底层,诚然,任何变换都可以转换为Map和Reduce, 但是要每个开发人员要直面MapReduce实在是有点开历史倒车的意思。 而且每个步骤都要写一个MapReduce,开发效率堪忧。
为了应对这一问题,Yahoo团队发布了Pig,它定义了一种脚本语言,可以转换为MapReduce程序执行。 使得开发效率得以提升,但并没有解决。 社区中仔细一想,既然是做数据处理,为什么我们不直接用SQL呢? 于是,Hadoop社区又开始进行SQL-On-Hadoop的研究,最终,由Facebook提交给Apache的Hive项目统一了局面。
然而这些应用只是在对Hadoop锦上添花,不能说是什么颠覆创新。与此同时,数颗明日之星正在酝酿之中。
Spark
在Spark出现之前,虽然也常有对Hadoop的抱怨,但毕竟已经是最先进的技术了。 说它繁琐吧,也有Pig,Hive来帮忙了。说它慢吧,也没有比他更快的了。 大部分人也就按部就班的用着了,但偏偏有人不服。
2010年Spark横空出世,带来了一副令人震撼的对比图,这张图至今还挂在Spark首页上。没错,Spark比Hadoop快了100倍。
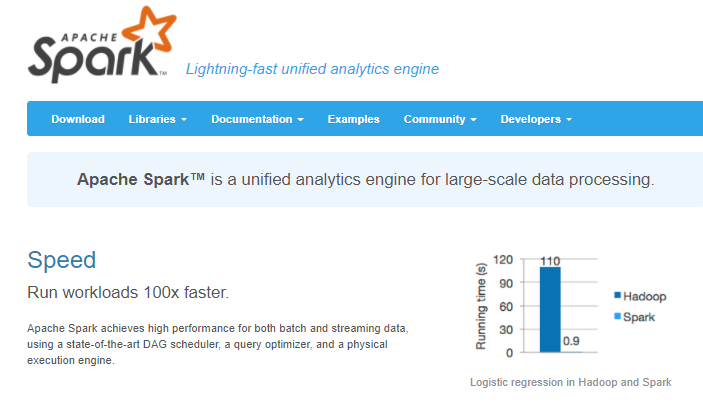
2009年,UC Berkeley AMPLab启动了Spark项目。 该项目的初衷是提供一种比MapReduce更普适的编程模型,并且提供容错能力。 次年,Spark在BSD许可下开源,2013年被捐献给Apache基金会并于2014年成为Apache顶级项目。 至今仍是Apache最活跃的项目之一。
除了快,Spark还带来了便捷,不同于MapReduce只有Map和Reduce,Spark提供了更高级的抽象,这使得Spark更容易上手。 比如说一个典型的WordCount程序,Spark只需要三行,而且非常容易理解。
val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
面对100倍的性能和更高的开发效率,许多公司纷纷积极拥抱Spark,这也进一步推动了Spark的发展。 短短数年,Spark又为我们带来了SparkSQL, Streaming, GraphX, PySpark, MlLib等等。 时至今日,Spark已经遍地开花,阿里,腾讯,亚马逊,eBay以及更多其他行业的公司都已经构建了基于Spark的数据平台。 可以说,Spark是Hadoop MapReduce事实上的继承人。
Flink
大数据持续发展让人们不满足于离线计算,一些场景下我们希望得到实时的计算结果,所以我们迫切需要一种基于事件流的实时计算系统。 虽然在此之前有Storm和SparkStreaming,但是他们各有缺陷,前者不能保证数据一致性,后者基于mini-batch并非真正的实时计算。 于是2015年Flink来了,它作为最新一代的实时计算引擎,汇集百家之长:
- 支持乱序处理 Support for event time and out-of-order processing in the DataStream API, based on the Dataflow Model
- 完全一次保证 Fault-tolerance with exactly-once processing guarantees
- 低延迟,高吞吐 Supports very high throughput and low event latency at the same time
- 背压支持 Natural back-pressure in streaming programs
Flink母公司Data Artisans于2019年被阿里巴巴以9000万欧元收购
Beam

2015年,Google发表了一篇论文The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing。 这一次Google学聪明了,很快就提供了一个实现,即Beam。
import apache_beam as beam
import re
inputs_pattern = 'data/*'
outputs_prefix = 'outputs/part'
with beam.Pipeline() as pipeline:
(
pipeline
| 'Read lines' >> beam.io.ReadFromText(inputs_pattern)
| 'Find words' >> beam.FlatMap(lambda line: re.findall(r"[a-zA-Z']+", line))
| 'Pair words with 1' >> beam.Map(lambda word: (word, 1))
| 'Group and sum' >> beam.CombinePerKey(sum)
| 'Format results' >> beam.Map(lambda word_count: str(word_count))
| 'Write results' >> beam.io.WriteToText(outputs_prefix)
)
Beam试图用一套统一的API来抽象数据处理的过程,下层适配各种运行时,例如Spark和Flink。 这大概就是所谓的“一流企业做标准”。 但是Google似乎高估了自己,大家喜欢的是便宜好用的技术而非Google本身,各大厂商并没有足够的理由采用Beam。 亦或是看透了“制定标准”的把戏,防止Google一家独大。 可以说,Beam的前景并不明朗,但是考虑到Beam到今天才5岁,未来尚不可知。
其他
上面说到的3种技术其实都只涉及了Hadoop MapReduce,时至今日,MapReduce已不再是首选的大数据计算方案。 除了MapReduce,Hadoop还有HDFS和Yarn,然而这些也都在新时代受到挑战。 因为除了大数据,还有另一个名词同样火热,那就是Cloud云。
在云时代,基础设施已经下移给到云服务厂商。 我们不再需要HDFS,取而代之的是Amazon S3,亦或Google Cloud Storage。 我们也不再需要Yarn,可以用K8S来管理集群资源。
前几年不断有声音在讨论is Hadoop dead?,而今这些声音越来越少了。
2019年,Hadoop的两个主要服务商Cloudera和MapR都开始进行艰难的转型,股价也遭受重创。
不过,Hadoop在云时代固然是美人迟暮,但是如果是在云之下,HDFS+Yarn依然是一个不错的选择。
结语
大数据技术是21世纪众多浪潮中灿烂的一朵,Google掀起了浪花,Hadoop涌起了狂热,Spark/Flink等后浪们又不断奔涌。 与此同时,在它身侧,云计算、深度学习、人工智能也一同翻腾。 从GFS论文的发表到今天刚好18年,大数据将要迈过成人礼,不知道在接下来的日子里又会带来怎样令人激动的新发展。